Raymii.org

אֶשָּׂא עֵינַי אֶל־הֶהָרִים מֵאַיִן יָבֹא עֶזְרִֽי׃Home | About | All pages | Cluster Status | RSS Feed
Icinga2 / Nagios / Net::SNMP change the default timeout of 60 seconds
Published: 16-05-2018 | Author: Remy van Elst | Text only version of this article
❗ This post is over eight years old. It may no longer be up to date. Opinions may have changed.
Table of Contents
Recently a rather large amount of new infrastructure was added to one of my monitoring instances. Using SNMP exclusively, but not the fastest network or infrastructure. The SNMP checks in the Icinga2 instance started giving timeouts, which look like false positives and give unclean logs. Raising the SNMP timeout for the checks above 60 seconds was not that easy since the 60 second timeout is hardcoded in the underlying library (NET::SNMP). This article shows you how to raise that timeout on an Ubuntu 16.04 system.
In the webinterface of Icinga2 the logs are unclean, making it harder to find actual errors:
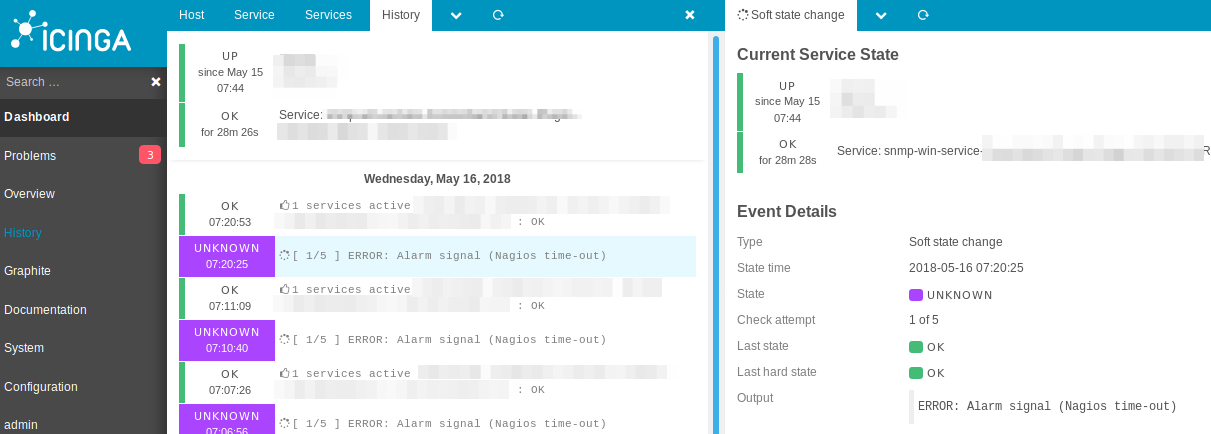
Timeout in the Manubulon SNMP checks
The plugins used for the SNMP monitoring are from Manubulon, Icinga2 has them integrated, and using Ansible I generate the configuration for the servers. An example apply rule could look like this:
apply Service "snmp-win-service-Microsoft-Exchange-IMAP4" {
import "generic-service"
check_command = "snmp-service"
vars.snmp_perf = "true"
vars.snmp_v2 = "true"
vars.snmp_service_name = "Microsoft Exchange IMAP4"
vars.snmp_community = "example"
vars.snmp_timeout = "60"
vars.snmp_service_count = "1"
assign where match("example", host.name)
}
All the variables can be found in:
/usr/share/icinga2/include/command-plugins-manubulon.conf
Raising this timeout higher than 60 gives an error for the check. Let's dive on the commandline and check what goes wrong:
/usr/bin/perl -w /usr/lib/nagios/plugins/check_snmp_process.pl -H example -C example -t 88 -n "Microsoft Exchange IMAP4"
Timeout must be >1 and <60 !
Looking through the perl code, $o_timeout is checked to not be greater then 60
seconds. Let's change that:
sed -i 's/$o_timeout > 60/$o_timeout > 900/g' /usr/lib/nagios/plugins/check_snmp_process.pl
Should be fixed right?
/usr/bin/perl -w /usr/lib/nagios/plugins/check_snmp_process.pl -H example -C example -t 88 -n "Microsoft Exchange IMAP4"
ERROR: The timeout value 88 is out of range (1..60).
And that error message is nowhere to be found in the plugin.
Net::SNMP perl code
This post (the site is behind a login now, so I had to archive the google cache, neat), had more information where this error came from, hardcoded in the SNMP library used by the Icinga2 checks.
I was unable to find out why this limit was choosen and not made configurable. This was the closest, but that does not give a reason. Now, 60 seconds is a long timeout and I'd also rather not raise it, but this case is an exception.
Change it in library:
sed -i 's/sub TIMEOUT_MAXIMUM { 60/sub TIMEOUT_MAXIMUM { 900/g' /usr/share/perl5/Net/SNMP/Transport.pm
Which does allows for a larger timeout:
/usr/bin/perl -w /usr/lib/nagios/plugins/check_snmp_process.pl -H example -C example -t 88 -n "Microsoft Exchange IMAP4"
1 services active (matching "Microsoft Exchange IMAP4") : OK
Not the most pretty fix, but a suitable workaround. Do note that my checks are not done every minute, but every 15 minutes or every hour. Otherwise it could clog up and cause a waterfall of load everywhere in this, lets call it vintage, infrastructure.
Also note that when you do system upgrades, these changes will be overwritten.
You might want to chattr +i some files.